I'm currently working on ML dataset engineering at Black Forest Labs. My interests are in creative AI applications, focusing on image-editing.
Contact at

A high quality image-editing dataset of 475k image pairs with an edit-instruction. Collected millions of high-resolution photoshoots, computed pairwise similarities, created an aesthetic filtering model & filtered from 30M pairs to the highest quality 1-2%, captioned with Gemini.


"photo, young woman in cyberpunk aesthetic, blood splatter, redacted, red numbers, canon eos r3, futuristic movie cover, dark gritty movie, bladerunner, femme fatale, 4k"
Introducing a method of editing photos using a diffusion model, preserving the structure and resolution of the original image.
First, I trained a ControlNet on a dataset of 1.3M portrait photos using the laplacian component of the images. Blending this output with the original image and then using laplacian reconstruction on the original high resolution images allows for generating edited versions of photos with a natural language prompt while restoring the structure and resolution of the original.
Strengths are single subject portrait images, preservation degrades for multiple subjects. Will look at ways to improve this in future work. Will release the code & dataset soon. You can access the model here.
Motivation
I am interested in how to bring the quality of the average person's photos & videos up to to the level of a professional photographer or cinematographer.
The way I think about this if at the moment someone takes a photo, you froze time and brought in a professional photographer with an unlimited budget to take the same photo, what would they do? They'd change lighting, composition, props, etc. These are the kind of changes the model should support.


"portrait of young man after a fight, backlighting, strong backlighting, 4k, canon eos"
This model has its limitations, but it's a great step toward this goal. Excited to build on this progress.

I've been exploring how the limits of art are changing with AI. One constraint that's being done away with is the scale of the art we can create. You can take any artwork and add an extension using AI.




My experience with Machina deserves a full write-up, will write this up at some point.
When speech-to-text models started to get good enough, I did only what was natural. I rewired a TENs (transcutaneous electrical nerve stimulation) machine through an arduino. Hooked up some players with a lapel mic, streamed this to a speech-to-text model, and then used the output to control the TENs machine through the arduino. The result was a game of Shock Trivia. The subject had to give the correct answer to a trivia question within a number of seconds to avoid being shocked.
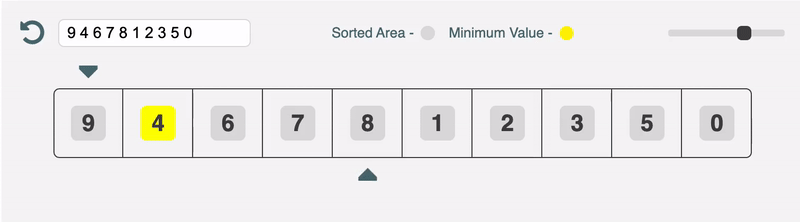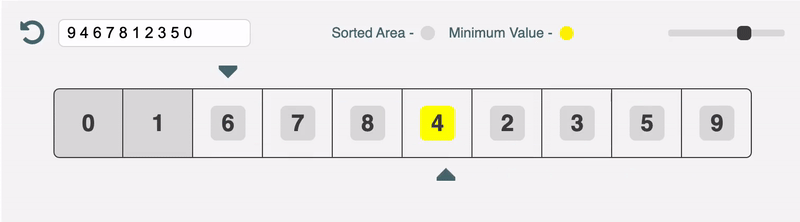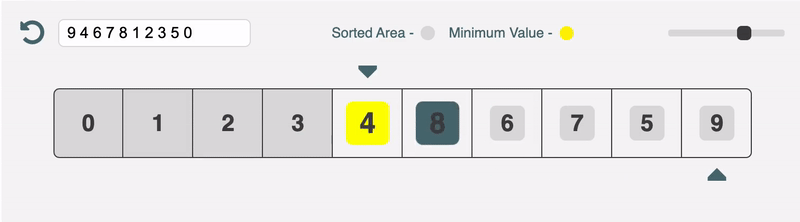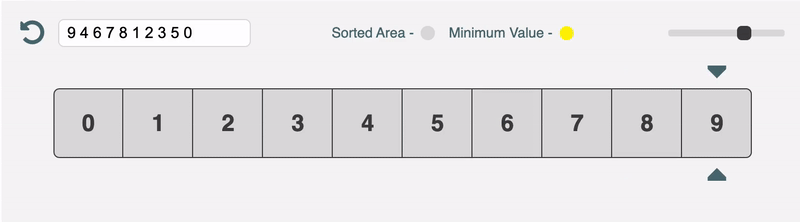
Reading the code first is a terrible way to understand sorting algorithms (and probably most algorithms). This project aims to solve that problem by visualising the sorting process with an interactive web app.
Interesting experiment into the top-down vs bottom-up approach to understanding concepts. Do you dive into the details or start with the big picture?
I think sorting algorithms are a win for the top-down approach. It is so much easier to grok the code when you have a high level overview and a visualisation of what's going on in your mind.